
One of the services I run in my homelab is the Cat of the Day (CotD). Over the past few days I’ve noticed that it hasn’t been sending out the pictures and inspirational quotes that my loyal user base (~10 people 🙄 ) have come to rely upon for their morning boost of positivity in the drudgery of corporate America. This must be corrected! With almost 4 days of downtime, I am clearly in violation of my 99.99% uptime SLA* that I’ve promised to my users. I am never going to hear the end of this…
Step 1: Understanding the Crime
I run the CotD on a Kubernetes cluster on Raspberry Pis scattered throughout my house. The first thing that I wanted to do was check into the status of past Cron Jobs, looking for logging information that I could parse through and see what had gone wrong. My initial instinct is that there was some issue with the scheduler and that it would be quickly resolved. Muttering to myself about “monitoring” and “alerting”, I vowed that I would fix this once, implement an automated solution, and never think about it again.

Unfortunately, I was immediately confronted with a problem.
$ kubectl get pods
error: You must be logged in to the server (Unauthorized)What? I know it had been awhile since I last logged in, but I don’t remember changing any passwords. In fact, I don’t even remember setting a password, since Kubernetes uses certificate-based authorization to do authentication. Was my cluster nuked? I went to a local DNS address on my LAN that hosts my instance of mealie and found that it was still up and running.
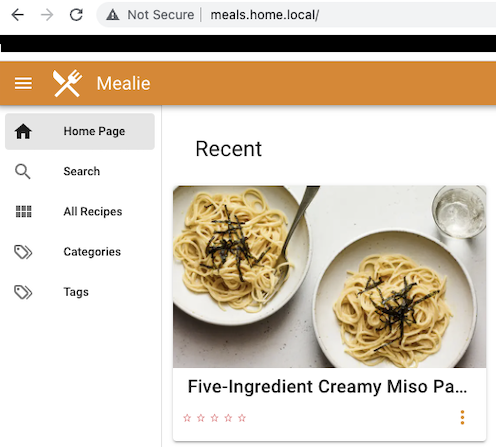
This means that my cluster is still up, running, and serving traffic. I just don’t have the ability to administer it, which is going to make troubleshooting tough.
Step 1.a: Getting Access to the Crime Scene
At this point I realized I was in for a bit more of an investigation than I had initially signed up for. I figured that on my local machine something was going wrong with the certificate that I was using to authenticate to the server. I had likely made some config issue at some point, hadn’t noticed, and needed to resolve it. In order to validate, I ssh‘d into the server itself to inspect the state of the cluster.
$ ssh kmaster
Welcome to Ubuntu 20.10 (GNU/Linux 5.8.0-1032-raspi aarch64)
... ubuntu Info ...
ubuntu@kmaster:~$ sudo k3s kubectl get nodes
error: You must be logged in to the server (Unauthorized)Wtf? Even locally, the root user couldn’t access the kube API. After a few minutes of thinking what could be happening and some quick Googling, it dawned on me that it must not be the clients that are at fault, the server is likely using an expired certificate. My cluster uses k3s, which automatically provisions a certificate for a 1-year timeframe and renews it if it’s expired or about to. I would just need to restart k3s to renew, and I likely hadn’t done that recently enough to re-provision the certificate. I restarted k3s, and BAM! Access restored.
$ sudo systemctl restart k3s
$ sudo k3s kubectl get nodes
NAME STATUS ROLES AGE VERSION
kworker2 Ready worker 336d v1.20.6+k3s1
kworker1 Ready worker 369d v1.20.4+k3s1
kmaster Ready control-plane,master 369d v1.20.4+k3s1Look at that! Cluster nodes alive for just over a year. Makes sense that the certificate would have just expired. Now that I’ve rotated the cert, I updated my credentials locally and I’m back, baby.
Step 2: Establishing the Crime Scene
As soon as I set my local machine to connect to the kube-api, I got a text. Because I’m easily distracted during these things, I checked it.
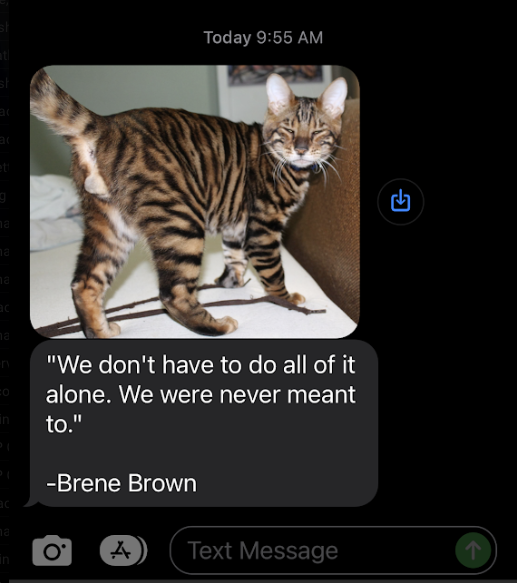
It looks like rotating the certificate caused the jobs that were not scheduled to finally be unblocked and resume activity. Because the 4 days of downtime matches up with the expiration of the certificate and the rotation of the certificate immediately resolved the issue, it was almost undoubtedly the culprit.
Step 3: Lessons Learned
Much like every time I learn this lesson, I need to implement a few things:
Regularly Maintain and Restart Servers

Turns out that regularly updating and restarting your servers for OS-level maintenance isn’t just something that’s a last resort. Keeping things up-to-date and restarting every once in a while is not only a helpful thing you can do for yourself, it seems like vendors like Rancher (maker of k3s) are actually relying on you to do it to renew their certificates.

Implement Monitoring!
I shouldn’t have to just realize that these texts aren’t coming to know something’s wrong. I should have some other process text me and tell me that somethings’ going wrong!
Certificates are Hard
This problem continues to show up in every workplace I’ve ever been in, and has now finally infiltrated my home. Having a good idea about how certificate works, how to rotate them, and what to do if they expire while you are still using them is always a good idea.
Conclusion
We are now fully back and operational. Cats and inspirational quotes are back to flooding my userbase with dopamine and continuing to give them a boost in the morning as the trudge to their soul-crushing workplace.

*SLAs are more of a suggestion anyway. I follow a more “pirate’s code” than “maritime law”