
This post is a continuation of Stocks vs Sports. Please see the previous post, Inception, for more context. See all the code on Github.
When trying to compare bets made on Wall Street against those made in Vegas, I’ll need data. Lots of data.

In order to do anything useful, I need to be able to obtain and store both stock and sports gambling data reliably. In the old days, this would be reading through the sports and finance section of the paper. Nowadays, I’m not even 100% sure that there is a “paper” to read through, so I’m going to be relying on different APIs that can feed data in real time. Recall from my previous post, Inception, that I’ll be using the Alpha Vantage API for stocks, and the Odds API for sports gambling. Testing these APIs is trivial as you can demo them directly on their website. Here’s an Alpha Vantage query with a demo API Key. Here’s the demo documentation for the Odds API. From an initial smoke check, it appears that they’ll fulfill all the needs that I have. In this post, I’ll outline the data generation component of the stocks vs sports system. To keep it simple, I’ll narrow the scope of the data generation to just the “stocks” side. I’ll create a follow-up post with the outline of how the sports gambling data is created.
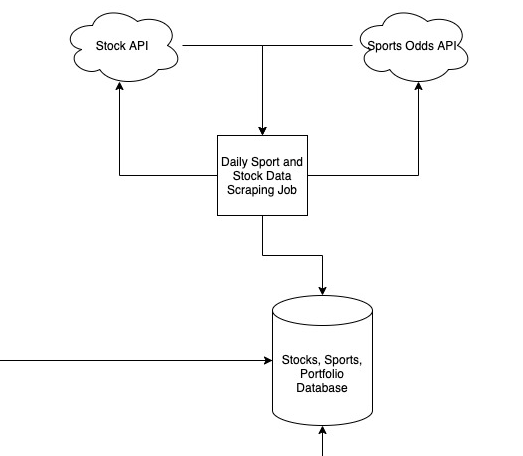
Data Collection Job
The logic used to collect data is very straightforward. Using the AlphaVantage API, I created a simple daily CRUD job that grabs stock data for the previous market day and inserts it into the database. In addition, I created a one-time back population job for historical data. I chose python as a programming language because I am familiar with it, it has an easy-to-use MySQL API, and allows pretty quick experimentation. If you know me personally, this decision will come as no surprise to you, as I have difficulty shutting up about how much I love python. In order to retain my ~4 readers, I will spare you the implementation details. If you’re really curious about the code, feel free to check out the repository on Github.
An Aside – Lessons Learned in Special Considerations for Non-Standard Architectures
I ran into an interesting problem during developing. Although I am working with a cross-platform programming language, one of the dependent libraries of the AlphaVantage SDK, pandas, does not compile on ARM64 architecture! When attempting to build a docker container based on arm64, I received this error:
10 1027.8 gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -DNPY_NO_DEPRECATED_API=0 -I./pandas/_libs -Ipandas/_libs/src/klib -I/tmp/pip-build-env-i8ze_k97/overlay/lib/python3.9/site-packages/numpy/core/include -I/opt/venv/include -I/usr/local/include/python3.9 -c pandas/_libs/algos.c -o build/temp.linux-aarch64-3.9/pandas/_libs/algos.o
10 1027.8 error: command 'gcc' failed: No such file or directory
10 1027.8 ----------------------------------------
10 1027.8 ERROR: Failed building wheel for pandas
10 1027.8 Failed to build pandas
10 1027.8 ERROR: Could not build wheels for pandas which use PEP 517 and cannot be installed directlyGoogle led me to an open Github issue outlining the problems with building pandas for ARM64 and indicating to me that this was a problem that doesn’t yet have a solution. No matter! I can simply use the raw API output rather than the SDK and move on with my life. Lesson learned: always check that your dependencies will run on your architecture. I intentionally and stubbornly did not learn a lesson in compiled vs interpreted languages. Python forever!
Back Population
The system requires historical stock data to compare against. Back-population reaches deep into the AlphaVantage API and grabs all the historic highs and lows for a particular stock for as long as it has been listed on the stock market. The back-population function is run as a single k8s Job.
2021-06-19 12:59:40 [ INFO] | stock_prices.py: 33 -- getting data from av api for MDLZ
2021-06-19 12:59:42 [ INFO] | stock_prices.py: 50 -- retrieved historical data from MDLZ -> sample: ('MDLZ', '2021-06-18', '61.8700', '63.1500')
2021-06-19 12:59:42 [ INFO] | stock_prices.py: 33 -- getting data from av api for MNST
2021-06-19 12:59:43 [ INFO] | stock_prices.py: 50 -- retrieved historical data from MNST -> sample: ('MNST', '2021-06-18', '91.6400', '92.9400')
2021-06-19 12:59:43 [ INFO] | stock_prices.py: 33 -- getting data from av api for MSFT
2021-06-19 12:59:45 [ INFO] | stock_prices.py: 50 -- retrieved historical data from MSFT -> sample: ('MSFT', '2021-06-18', '258.7500', '262.3000')
2021-06-19 12:59:45 [ INFO] | stock_prices.py: 33 -- getting data from av api for MU
2021-06-19 12:59:46 [ INFO] | stock_prices.py: 50 -- retrieved historical data from MU -> sample: ('MU', '2021-06-18', '76.1300', '79.2835')
2021-06-19 12:59:46 [ INFO] | stock_prices.py: 33 -- getting data from av api for MXIM
2021-06-19 12:59:48 [ INFO] | stock_prices.py: 50 -- retrieved historical data from MXIM -> sample: ('MXIM', '2021-06-18', '99.3900', '101.9400')Daily Population
In order to keep data relevant, I run a Kubernetes CronJob every day except Sunday and Monday to grab the data from the previous day’s stock market. It iterates through the list of tracked stock tickers, obtains the high and low values from the day, and inserts them into the database. In this way, the numbers are no more than a day out of date.
2021-06-21 13:52:42 [ INFO] | db_functions.py: 55 -- obtained db connection to stocks_sports
2021-06-21 13:52:42 [ INFO] | main.py: 95 -- run daily population
2021-06-21 13:52:42 [ INFO] | stock_prices.py: 31 -- retrieving date: 2021-06-18
2021-06-21 13:52:43 [ INFO] | stock_prices.py:110 -- Retrieved daily stock: AAPL, hi: 131.99, low: 130.15
2021-06-21 13:52:43 [ INFO] | stock_prices.py:110 -- Retrieved daily stock: ADBE, hi: 572.98, low: 556.39
2021-06-21 13:52:44 [ INFO] | stock_prices.py:110 -- Retrieved daily stock: ADI, hi: 166.22, low: 161.47
2021-06-21 13:52:44 [ INFO] | stock_prices.py:110 -- Retrieved daily stock: ADP, hi: 196.24, low: 192.18
2021-06-21 13:52:44 [ INFO] | stock_prices.py:110 -- Retrieved daily stock: ADSK, hi: 281.13, low: 273.8421Together, the daily job and the back-population cronjob allow for continually updated stock data. To allow this data to be stored for quick retrieval and data analysis, I created a database.
Database
I chose a relational database to model these data points. My rationale is that relational database do quite well with normalized data, I have some experience working with them, and MySQL has an ARM-compatible docker image. Therefore, I knew that I could deploy it into my cluster and that I could use standard SQL syntax to interact with it.
Data Model
The data model that I’m using of the stock market is outrageously simple. I am limiting the scope of the stocks that I’m retrieving to the NASDAQ-100 for simplicity, and I’m only storing the low and high values for the day. Of course, there are millions of other relevant data points to the performance of any stock, but I want to keep this project as narrow as possible.
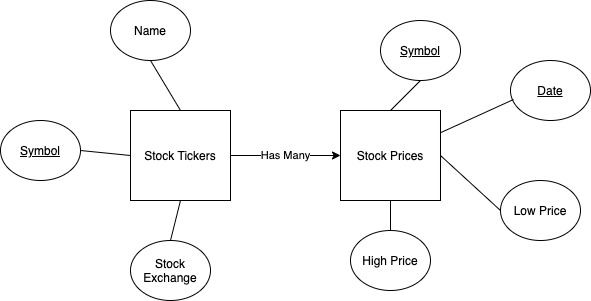
Once the data model was created, I just had to create a couple of SQL scripts to make tables, users, and some other initialization values, and I was on my way to deploying a database!
Deployment
Learning how to deploy MySQL within a k8s cluster was fun! It is a lot different from local deployment, which is as easy as setting up the MySQL daemon and going wild. For k8s, I had to remember a few things:
- I’m deploying a stateful application to a stateless platform, therefore I should use StatefulSets as my workload controllers
- StatefulSets will need to be back by a PersistentVolumeClaim (and associated PV) in order to enable state
- I will be communicating over k8s’ internal DNS, so I’ll need to provision a Service to access the DB
- Secrets are necessary for managing the admin account as well as the user accounts that will be accessing the DB
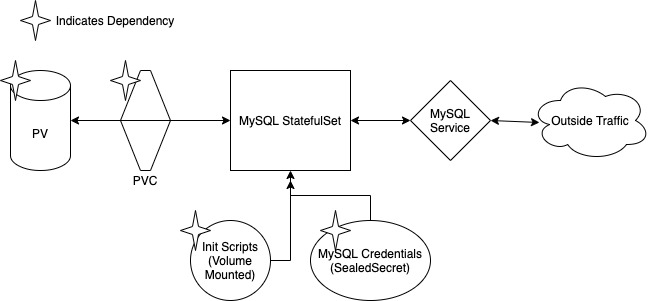
I’ll tackle these one at a time.
PersistentVolumeClaim
In order to create state, I need space on disk somewhere. I used an NFS StorageClass. Developing NFS on my NAS is an adventure in itself that really deserves its own post. What this PVC allows me to do is request a certain size of volume. The k8s storage manager will then reach to my Synology NAS and provision a directory of that size if the space exists. The PVC definition is as follows:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-pvc
namespace: stocks-sports
spec:
storageClassName: nfs
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10GiWhen applied to the k8s cluster, a PVC and PV are provisioned for use with anything that wants to claim them. In my case, it’ll be the StatefulSet.
$ kubectl get pv,pvc -n stocks-sports
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-53a618e9-16f5-404d-98c1-e1f676b0b1d9 10Gi RWX Delete Bound stocks-sports/mysql-pvc nfs 4d22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/mysql-pvc Bound pvc-53a618e9-16f5-404d-98c1-e1f676b0b1d9 10Gi RWX nfs 4d22h 
Credentials
For anything to be used by MySQL, it needs user accounts. They need passwords. I am not exposing this database to the outside world, and so it is effectively “airgapped”. Why do I care about credentials? Shouldn’t I just set everything as admin/admin and move on with my life? I could easily do that, but I love over-engineering my solutions! Since there’s no deadline, I don’t feel the need to do things in a constrained way, so I made a production-ready solution for no good reason.

One of the complicated problems with k8s is that by its declarative nature, all configuration should be done as code in source control. Secrets are one of those things that you’d rather not have in source control. How do you reconcile this? Fortunately, Bitnami has come up with a good solution with SealedSecrets. Sealed secrets are secrets that are not simply base64 encoded, as k8s secrets are, but are actually encrypted. They’re decrypted server side and create plain k8s secrets that can be used by other k8s objects. Creation of the secret involves piping the output of a generic k8s secret into the kubeseal binary.
$ kubectl create secret generic mysql-credentials --from-literal=root_pass=<secret> --from-literal=admin_pass=<secret> --from-literal=writer_pass=<secret> --from-literal=reader_pass=<secret> -n stocks-sports -o yaml --dry-run=client | kubeseal -o yaml - > ops/db/mysqlCredentials.ymlThe resulting YAML file is encrypted and safe to commit to source control.
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
creationTimestamp: null
name: mysql-credentials
namespace: stocks-sports
spec:
encryptedData:
admin_pass: AgCTkzJu9+ueqOC7Xb2ZXvQNhkLTc+LuMnGCkAvy6EBMkRlg6jwMdzGf/SsnKdLovzLyLtnr3froq9BInF4A6cVTAHo/ftT5lAdSlLbPvW6E+5Ooh40yvcmUPG2kZ/VtLHdW1Egt+V4sQ6WS2TH+2SZV6jGxsCZzBOHDGtPRIhZZ8jv4EVhOMZTWeDp0QkRILY/fsnuOFkrrlvqi8hkpCfEA0Io6WJ5XLrVAAnMzZOcBSRMv7uTy5WZwywgvllXCfY1ReaKX+8ccxrbP8VXMI9fccQcHxPHmJ1E9qVkzrc9qjcrWM2V+pvI5ZWXU7hZHFhzx8i2LhrwrcC6QDy8DOm3PxhbkKNOhtyd0YQxC/OGn3iHAWaYtPB0Jb72nKHLznSVG4E0ql5SthLpdbNes5jgXozccI+hTv9NHvrId07+IUwXWo0/NrIjeiIX58w3/O93quVV7GriqzK3YaYOsb7NVdKHn9/k+P4oaRcbPNwT7L1zdakv0ajnLDc9cI8Cju2OcXRvR6QX3FUPzKQgT1XyUK2RBxrRN9XiIq9oqyuLsUfBJvzST2L7AEym3LnfWB+wE9nTxhY7KIjYTBomFOfV/YByGNl3H9rc0m8p2XoOptYrH8omzJi3MOPNJ2ggfPEqLS+uEh6SPEhrtHKkxgmjNCNrVkltouDp2/wVK60O2YcGEgx9XRrJzKNwVVqHNrbk+aNqRKkkmfTqJ7uD6FJfpITG3Kg==
reader_pass: AgAzjRUhQr5DDaKnLF5VnDRZgCa62UseB3j3Y8MwjmqdH9HxUU21lTF76d+rkWwHKkoqk3TK5DyJfav639NRsQ0qJD3nK6PHUd0Q4r4uprtR9YVUDlZtWLoJcHKH9xIqN2KM3CvLp6lW+NCUgHNLAhoPFpfyIVRRmIkBOakDVEBYHDsTX6o2t2a1pQS5XwlRw30beqOPhxHoANG8qo15YVI4KmdK4uPWD2PvnT10F4Zim35p5GRGWLuxFK4mUrzA3MRAOGEfTaopdphzxru23ajnPuXiXhNC/g8Xm4IkTz6kWK5E3mDslalu9ZIpAoePmD0xU5tQwXSKko38uCe8qVhlO8EyFhUTkWJ8YxVc/ZQBOr/Aqp+/TNfipZRo20D7PrZPpUPVREGNq4nVUAp6raFfhPZokLmB5AFHhtPZt6jnu3mTUwRDuOGvC+n5avywxkZ69Mb6DP39E1erpEJJ4sfqoF8z/30BsT2SdbYs5Bj9CgcySijLwGSoQNoi0EN5h/C6sToYv04fSa1QeWIyNl2jpP0cUKVR8XNSZBMdRMTIHt6g06g0tp4pps8hTG6J5SnvpB+luX66Wlk0QF7QK7r6OFZsXu82nfIa//hwkHLY6lLYwDISEWNxfHBNHVqftaIVbgxhweS0yUCsh9+Oq/8t2Gr0aLkoHV28oOUsin0eN1j2uxioW+ND48Ri/zJrhNewjtYcGwpVEVy8+c7P9t70VkZMAQ==
root_pass: AgAIuGlgYASrmyiJH2TaWry6G2vlizr6ob1gyrK3lOHw2OFQ60LCeqX2ethV1m6NijdbZMr1H5rZSmTQmHs9UTE4H8rm3AsbA0qZJ65FHEzOal8yXX5BOLuGeEqg61hH/2JK2L0vXiNHtXVmX7C+Rfsd0sWPagWa0AqYDP0OEg7Y516jU6aNEujfPT5/830W/curIRrbcX/cinELbYCz7Z2rihnwIPOAuNc5lSfYiwksk3C0fKevbEDTrxMscMz53M/t7noVN5iU4CkWIEXcXtuJXzG4SQ7xXl+ZTJMNhUOBmvYdZCmHzmSx4n9o9QsnOB7FG0CTSR8d5ZSVSiZto0g0W2MUtmi+4qI0aA09KXKar9okNDIFHRT3j0/48jyefiusJJN3P/KJqAMINjeKKS+aGLvGitzZO6+1x2gEItK7HBbLUiGtqvhWEmZ8aSMnsyoTLIpUttWsTGUg6RKvrkmzK+i+AhV48LKbVZgWLnWu3RFyMFsaJvHbM01GHQ180JI/TOMRDSOIlTzHrsuhv8+vD+swX27GBLccJF8gZKcPsXlUJFGBNOurndxwXkug2n0J/tpUc4hRRiTx5SAamZ5LPbINnojEGE7T5Yr9MbASns/NXKjDHG6CQ9mZtrXxxfLaOV47bl1/oyZhhtfusAzH0QwZJ2Cy4NLOQhrK1/w7rRQ/4TZOS4IQlQdE7ZFF+Lwr27eiGJ7H+CptGbLhcMHCxSvGQg==
writer_pass: AgDDL9eUn1zlb+Pi+OQPk13ZRYjBBpBElq4hh/9KM9Iuf1vUvxc+xhmoQa7d0x9bZpVwXsWDspBojD9iMI+m/bv97RrdK6eyKur1CHZDS5P85FZWjXofKD6+dqgDTKHAPt+uRw0YxcihYK6dF5BvxgeUfH3tqg6DsM9Du7J9dzV7RpB2GyoaTnT/Zbsb5GNXcFWqRkgT6xGqX9Ay5txuOe+XJBuyYUCVj70Ajs16SN6KM7DfIvwbM+/aB6n0KPbEpkVPpKQulsVqRAcpEFGDPEiCthhwkqQWJzHpFIxr1em/mvUvj6igXasSQsHCBe+wiaQMTavQ4r863Aai8eC9m3lzEjg0B7Nk9ki4OEqAMf4cR0WOkNkpU48IS61J2V1ClE/neUDJvfpjr3hkyv0LU9dHlWsjNTdAWakQVrdfMsRrwoZG6tJJSZyZUQwkjJdt9LXH3Uxv886VPgs2MnCfV77NGdLXduAzzGpZALQTb+eJKxa5hnq9LxD1ar9YBDsB/havyPItAZ3OOQkiEcRU7vyiqA7bxVUNs1VegSED/BShFsnwjh9ejOcSWktq4UKQtSW3GN98yBfDCIyytkDXflxrzUu8ZPG9Vio+4VZZb8xOIJM7cHOwAiJ5e27Ec3nq+VHjIVeAg62a2IekQbFmsuZtbeiRfKw9hly2+fuD7Use960BSVhIYXvueMpysLrhwPwziGiQRODpdBtogHoRCPRMM6XtbQ==
template:
metadata:
creationTimestamp: null
name: mysql-credentials
namespace: stocks-sports
Startup Scripts
In order for the MySQL Server to be resilient, it has to be able to be killed and restarted without dropping functionality. That requires startup scripts to be run to configure the database to have appropriate tables and users to make this all work. When creating databases and tables without sensitive information, they can be stored in plaintext in ConfigMaps and simply mounted into a special directory called /docker-entrypoint-initdb.d/ on the MySQL container. All sql scripts mounted to this directory are run when the MySQL server starts. The initial startup script will create the database and necessary tables.
apiVersion: v1
kind: ConfigMap
metadata:
name: startup
namespace: stocks-sports
data:
init_db.sql: |
SET GLOBAL time_zone = '-7:00';
CREATE DATABASE IF NOT EXISTS stocks_sports;
CREATE TABLE IF NOT EXISTS stock_prices (
symbol VARCHAR(10),
date DATE,
low_price DECIMAL(20, 2),
high_price DECIMAL(20, 2),
PRIMARY KEY (symbol, date)
);
CREATE TABLE IF NOT EXISTS stock_tickers (
symbol VARCHAR(10),
name VARCHAR(255),
exchange VARCHAR(50),
PRIMARY KEY (symbol)
);Because I’ve added users, I also created a script to insert them into the database that should run at startup. Unfortunately, I wasn’t able to figure out a way to obscure the secrets from the actual script itself. I’m sure it’s possible, but I found it easier to actually just hardcode the values and create a SealedSecret from the script itself.
USE stocks_sports;
CREATE USER IF NOT EXISTS stocks_sports_admin IDENTIFIED BY 'admin' PASSWORD EXPIRE NEVER;
CREATE USER IF NOT EXISTS stocks_sports_reader IDENTIFIED BY 'reader' PASSWORD EXPIRE NEVER;
CREATE USER IF NOT EXISTS stocks_sports_writer IDENTIFIED BY 'writer' PASSWORD EXPIRE NEVER;
GRANT ALL on *.* TO stocks_sports_admin@'%';
GRANT SELECT on *.* TO stocks_sports_reader@'%';
GRANT CREATE, INSERT, SELECT, UPDATE on *.* TO stocks_sports_writer@'%';Of course these are not the actual secret values. Or are they?
$ kubectl create secret generic mysql-startup --from-file=./db/users.sql -n stocks-sports -o yaml --dry-run=client | kubeseal -o yaml - > ops/db/startupSecretScript.ymlapiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
creationTimestamp: null
name: mysql-startup
namespace: stocks-sports
spec:
encryptedData:
users.sql: AgCEYdL+ZWTLm35qxbatMddUtOl1a7ukuWG4mtyIVZlLSv8lm0OQe3hsrMCXXe17RFRAFSERTqsAwaO+TXho+hMbZumlvjOg1oxyZw7RgW23kKq65NrTrjtrLuxqCsmxL6SNSaJG/zXyIkzcF4Iu9FkZXm+aJL+Ys9tb2TAS1paeLpXJA1X7o0jvsIRMQekZ1iCAMpPPwNbDZI8s9EwpGragzsH4BLigE7e2DPIgysh6a1VMlGB6MwsJYS1Kkqw5Ifva3HwWrIbUXrK93SJbMMwkS1IA6MECGHSz99nnqJOMg/ZSREnq+3ccio7K1DWeCEEepp+oLu+/uRNpI/SU8eA8p8pzlwHvpEAOrtiuQTh2b2xhN5oUTFQLdTnTVKkIvmclDTeJfMKYVGwDFi+ZExyr4oJZtEHrhJy/qYKliBNiCZQree2IrnnOOFTW4JP6ICyH63hZLmSWKDHc0Y4CSkeQDs+eVE3hMajgFoqfEOsrgfnLN/3cBlhwt1lquOtYy/UMQj5ajKHn0W15Ib44wNoR+d6ciBoWf8E0UD0nwXe1OUtbGAeetx8l668ru24pVftlA7jO/NRjf5w406ssna8eGKGyDPUy1+8BH0I3TDi8AiViX660jd1lqUEP6eF9fQQOewuaR1EFjpzZdtXa7beJPMKeoZ6ixNshngcrBjCSRmnbFiW/KcIVj03/mfZgWSJamgNtf2irGihzHPjmRAF1ZryiEbO71ep3gg8A/E0HqqE9OUclsZ3MBZVA4mS9Vg0bZ+Qizbh/iCehrEvwxWUfM664IKdnzCSdkM9QIMlhtVIBxdl/HtwKeNvTdp5QvDjoJELlWndHAO4gmtK6NypDRZQs0T478cok9qTc5x91lZROn/oulON8dXI8mkhC6Xy4RblYIDbgI/4Y5VeEdOf7HCVZ8geiA9XMSWcXiFAj4m1wDFobvqnA43erGgw318se1TJabewmH73LkKyqme+X7ydjOCe8zVW0q3RUDbDgB4roxlqrZVEuTEQXEH+5A1cG2PnXYVRT8CXzfh/nLw3frR6lR/ivcMKkkT3VphKbJd8zsTor1Qim3vS5xI7jZlBjC5GOf7obf1LhWS3n1RL44GkaS9gRFMwc3vcaJvLrUTUy8hMF98xg5vN7kVhEDXpevhx/SQYgLc3/1JaQbkG5rd+Um5FaPZBdMZfhh/d0xx4tWnm4UxglujDsbstaocK2MkDNQoViAYk3iayDM3ooj0aqv9P+0WLfQpvrLZk3xsdHD6cX63UXmZ4IYmxeixsqvRK4gcpjcONJdW7up3fa11JH+iqhlz8u4y5UzY+1rUsKhD7Ir22IEtYvRuUNciTxtAfsoz70g1sXrrhqasV/AW+bNqrAs44LoaI=
template:
metadata:
creationTimestamp: null
name: mysql-startup
namespace: stocks-sportsStatefulSet
The MySQL Server is provisioned using a StatefulSet. While an STS introduces overhead that is not present with a Deployment, they create sticky identities that keep storage and networking easy. They are the preferred method for running applications that need state. Databases are, by definition, stateful applications. It’s a logical choice.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: stocks-sports
spec:
replicas: 1
selector:
matchLabels:
app: mysql
serviceName: mysql
template:
metadata:
name: mysql
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql/mysql-server:8.0.25
ports:
- name: mysql
containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-credentials
key: root_pass
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
- name: mysql-initdb
mountPath: /docker-entrypoint-initdb.d/init_db.sql
subPath: init_db.sql
- name: mysql-init-users
mountPath: /docker-entrypoint-initdb.d/users.sql
subPath: users.sql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pvc
- name: mysql-initdb
configMap:
name: startup
- name: mysql-init-users
secret:
secretName: mysql-startupNote that this definition makes use of several of the other dependent objects created before it. It adds persistence by mounting the PVC as a volume at /var/lib/mysql. It adds the startup scripts as objects in /docker-entrypoint-initdb.d/. It adds the root credential as an environment variable. Neat!
Service
The service object is dead simple. It simply exposes the MySQL StatefulSet to the network at mysql.stocks-sports:3306. It is now ready to be used!
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: stocks-sports
spec:
selector:
app: mysql
ports:
- port: 3306
targetPort: 3306That concludes all of the database-related objects.
Next Steps
The next thing to do is begin collecting sports data and entering it into the database side-by-side with the stock data. Because the database is already provisioned and configured appropriately, the work should be much easier. Famous last words…