
I love gambling on sports. I never win money, but adding a bit of risk to an otherwise mundane matchup can make watching games more exciting. I don’t love gambling on the stock market. It just isn’t as much fun. In both cases, I take my money and use it to buy a chance at more money in the future. Where the outcome in sports is influenced by the competing teams (and in some cases, the referees), the outcome for stocks is controlled by any number of “animal spirits”. The uncertainty of the stock market clearly has many influential factors, from normal market fluctuations to public manipulation. Yet gambling on sports is viewed as a riskier and less lucrative proposition. Does it have to be? A savvy investor will likely outperform a savvy gambler, but what about an idiot like me? Is there actual historical data that would support that if you bet with no strategy and invested with no strategy, Wall Street would win out over Vegas? Is there a way to beat the odds by using my rudimentary data analysis skills? Of course not! But I still want a way to answer these questions with a silly and over-engineered solution.

One of the awesome things about working as a software engineer is it allows me to build extremely large and complex solutions for problems that aren’t demanding an answer in the first place. Over-engineering solutions is a lot of work, but it’s a lot of fun. In my case, I’m looking for the solution to the question: does a randomized strategy for sports picks outperform a randomized strategy for picking stocks? I’m confident that the answer will be no, but I want to design a system to explore the problem space anyway!
System Design
The application I’ve designed is not complicated once it’s broken down. It has a few quirks beyond a simple IO interface because I had to keep in mind the constraints of my hardware, but it is basic enough to allow for future extensibility. I’ll start with some requirements.
Requirements
Because I don’t have any customers, I get to make the requirements myself! In addition, because I don’t have deadlines or shareholders, I can make them “goals” rather than requirements. It makes my job a lot easier. Some of these goals are:
- Stock data should be accurate as of the previous market day
- Sports data should be accurate as of the start of the game
- Narrow scope of stocks and sports for MVP
- As much of this as possible runs on my Raspberry Pi Kubernetes Cluster
These goals aren’t super concrete, but they’re enough to get me off the ground. After some initial whiteboarding and some quick analysis that is likely inaccurate, I came up with this system diagram:
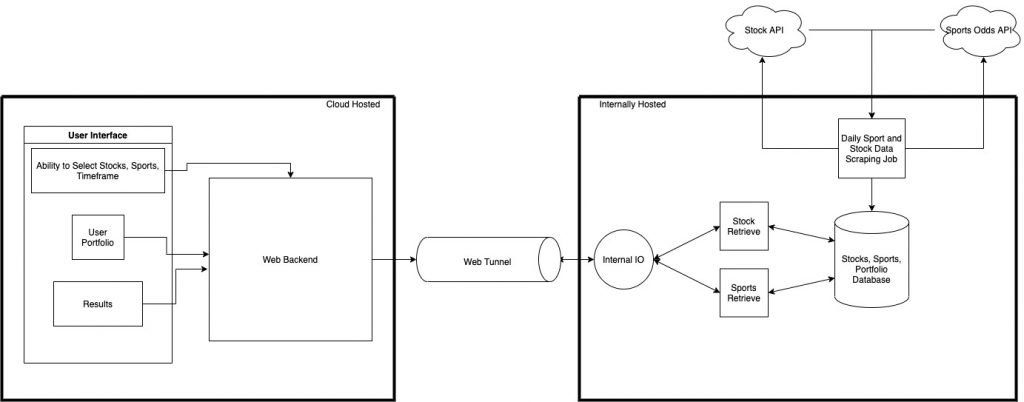
Seems a little complicated for a straightforward CRUD app, no? I designed it intentionally this way for the constraint of my hardware. I have a Kubernetes Cluster running on my home network, which is not exposed to the internet. It would be nice if this could be publicly available, but I’m not willing to open my internal network to inbound traffic. The “real” solution to this would be to put the business logic and database into the cloud, but gotta use my homelab for something! Otherwise it’s just a fancy electricity drain living on my bookshelf. The access problem is solved by implementing a tunnel between the public internet and my home network. The rest of the design is rudimentary. To get a better idea of the individual components, let’s break them down separately.
Data
The first thing that I’ll need to obtain is data. This entire project is unusable without a data source that can reliably deliver both sport and stock information in a reasonable timeframe. Once I have the ability to programmatically retrieve data, I can begin storing it in a persistent database for querying and manipulation.
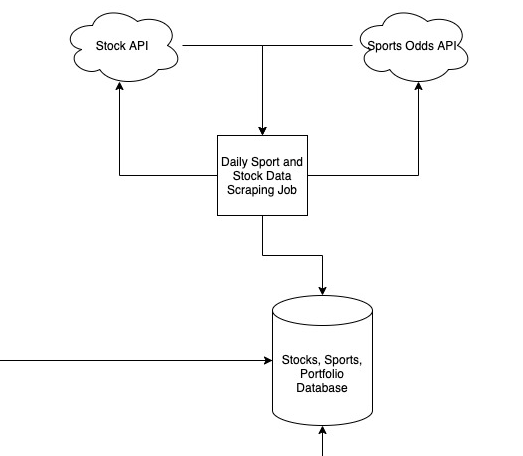
Formulating a well-formed and optimized database can allow for further extension of the project. For example, if I want to create a prediction algorithm that uses historical sports gambling data to predict future performance, this database should have the required data points. Although every investment ever will come with a “Past performance is no guarantee of future results” disclaimer, at least one academic paper suggests that line movement in gambling may be a relevant factor for betting strategy. I have no doubt that Vegas is aware of this, but if I have a well-formed data model, there are a lot of different possibilities for exploration.
Sports Data
For sports data, I am using the Odds API. It is simple, has a lot of viable sportsbooks, and has immediate data for the sports that I care about. The rate limitation of 500 requests per month is pretty strict, but it is enough to be usable when getting started.
Stock Data
For stock data, I am using the Alpha Vantage API. It is a free, rate-limited API providing historic as well as up-to-date stock performance data. It has a vast array of capabilities, but I’m largely keeping it pared down to the opening and closing prices of stocks on a daily basis.
Data Querying
The ability for the end user to retrieve data from the database is necessary if we’d like to do anything useful with the data.
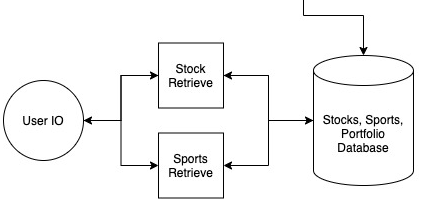
This simple service creates a “thin layer” to decouple data access and a user interface. This is a common design pattern.
Tunnel
This is a big challenge that I’m not 100% sure I have a solution to at the time of this writing. There are a few services out there that offer the ability to tunnel between cloud and “on-prem” via a proxy. For this project I’m going to be messing around with Webhook Relay. Webhook Relay creates a tunnel between an HTTP endpoint they host to an agent hosted in arbitrary infrastructure. In my case, it means creating an ingress controller on my cluster which can then forward traffic to the internal thin layer for data processing.
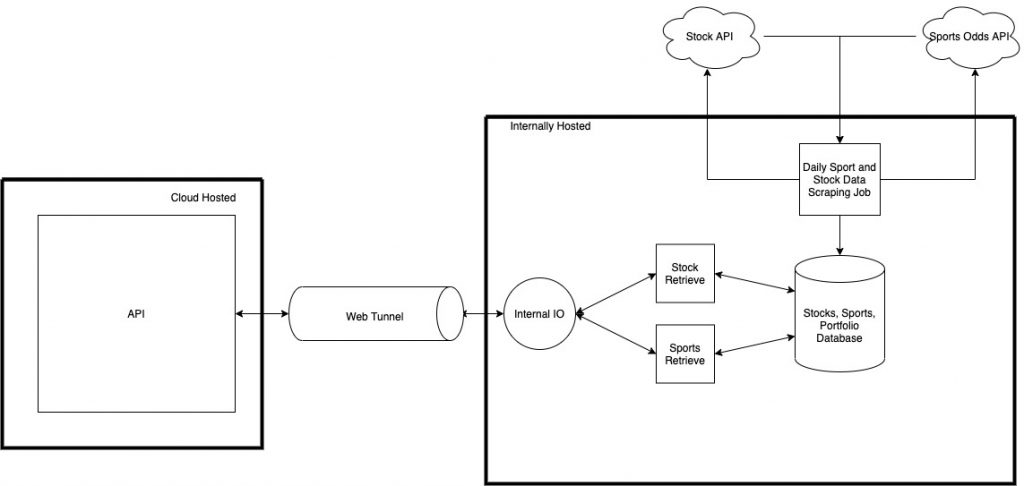
By deploying an external API that is available over public internet, I’ll have all the framework necessary to have an actual end-user-facing application. Of course, it will only be usable via one or more REST endpoint(s), but the ability to communicate with an internal database from the outside world will be a huge accomplishment within itself.
User Interface
In order for this project to be useful beyond my own curiosity, it’ll need some sort of user interface. I don’t intend to create something as feature-rich as a standard web application frontend, but I would like to be able to have a web page that someone with minimal technical skills could interact with. If that’s something as simple as a web form with a drop-down box, I’d be happy with that.
Minimum Viable Product
The minimum viable product that I’d consider “done” is something that fulfills the listed requirements and can do it over the public internet. For the first iteration, it does not need a fancy UI with a client served in the browser. It can be something as simple as a REST API that responds to a few well-defined inputs like “available stocks”, “available sports”, “odds for game on date”, or “stock price as of date”. Eventually I’d like to be able to have a “portal” that can be used for things like having an account, maintaining a “portfolio”, and tracking your predictions over time. With a well-designed data model and an effective API, this should not be impossible to accomplish.
Milestones
[X] Write Design Documentation
[X] Develop and Deploy Effective Database – See 1.a
[X] Develop One-Time Back Population Job for Stocks – See 1.a
[ ] Develop Automated Data Population as Daily Job
[ ] Establish API Contract for “Thin Layer”
[ ] v1: Develop Internally Queryable API Layer for Database
[ ] v2 (MVP): Publicly Expose API via Tunnel
[ ] v3 (Stretch Goal): Basic UI Deployed Publicly